Odysseus AI Ollama models in one minute
The short answer: use one small Ollama model first, connect it with the correct OpenAI-compatible endpoint, test a plain chat prompt, and only then try larger models, Cookbook recommendations, agents, or deep research. A good odysseus ai ollama models workflow proves that the model route works before it asks your machine to run something heavy.
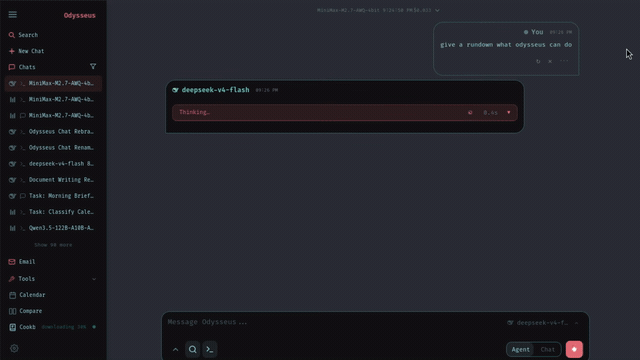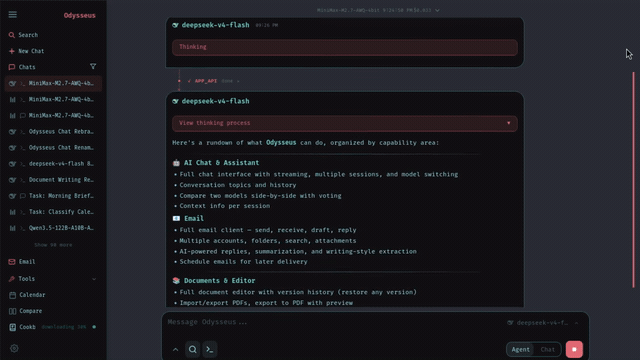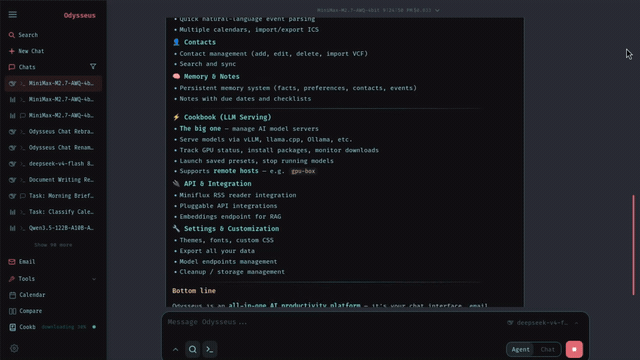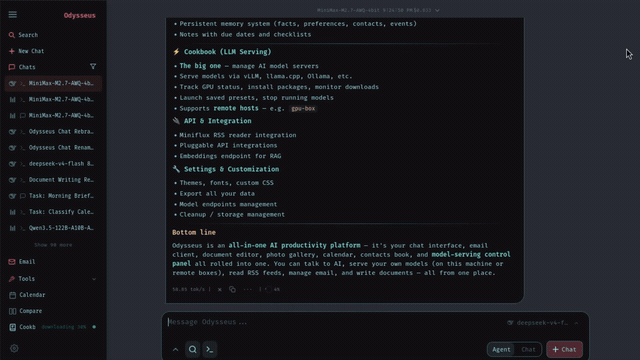
Odysseus is the workspace. Ollama is the local model server. Cookbook is the hardware-aware helper that can recommend and serve models when the runtime path is available. OpenRouter or another API provider is the fallback when local inference is too slow. These are related choices, but they are not the same choice. If you mix them too early, troubleshooting becomes unclear.
The safest first test is boring: run Odysseus, make sure Ollama is already serving on your machine, pull one compact model from the official Ollama library, add the endpoint in Settings, then send a one-sentence prompt. If that works, your Odysseus AI Ollama models setup has a stable baseline. If that fails, fix the endpoint or pulled model list before testing agent features.
Use the right Ollama endpoint
Most failed Odysseus AI Ollama models setups are endpoint problems, not model problems. Native Odysseus and native Ollama on the same machine usually use http://localhost:11434/v1. Docker Odysseus talking to host Ollama usually uses http://host.docker.internal:11434/v1. A LAN model server uses the private IP of the host machine and should stay firewalled.
The /v1 path matters because Ollama provides OpenAI-compatible endpoints. Odysseus can connect to providers that speak this style of API, but the base URL must match where the server is actually reachable from the Odysseus process. In Docker, localhost points inside the container, so it cannot see host Ollama unless the routing is mapped correctly.
Native same machine
Use localhost:11434/v1 when Odysseus and Ollama both run directly on the same operating system.
Docker to host
Use host.docker.internal:11434/v1 when Odysseus is inside Docker and Ollama is a host app.
Remote or LAN host
Use a private host IP or VPN name only after authentication and firewall boundaries are clear.
If Ollama is not listening outside its own loopback interface, Docker or LAN clients may still fail. The official Odysseus README notes that host Ollama can be served with OLLAMA_HOST=0.0.0.0:11434 ollama servewhen you intentionally need the host to accept connections. Do not use that setting casually on an untrusted network.
Choose the first model by hardware
YouTube videos often highlight exciting model names because that earns attention. A searcher needs a more practical answer: choose the first model by hardware, latency tolerance, and task type. The best Odysseus AI Ollama models for a first run are usually compact, current, and easy to replace.
Low-memory laptop
Start around 1B to 4B class models. Expect basic chat, summaries, and simple rewrites, not heavy research or agent planning.
Modern Mac or desktop
Try 4B to 8B class models first. If responses are smooth, compare a larger model before using agents.
Dedicated GPU machine
Use Cookbook fit scoring or Ollama library sizes before trying 14B, 30B, or larger models. Watch VRAM and load time.
Weak hardware
Use API-backed models for quality and speed, then keep Ollama for private small tasks or offline experiments.
As of this guide, the official Ollama library lists current model families such as Qwen3, Llama, Gemma, Phi, Mistral, and code-focused variants. Do not hard-code your long-term model plan from one video. Visit the library, check model size, pull count, tags, and intended use, then test your own prompt inside Odysseus.
A simple testing order works well: pull one small general model, send a short chat prompt, try a short coding or writing prompt, then compare one stronger model. If the larger model is dramatically slower but not clearly better for your actual work, keep the smaller model as your daily Odysseus default.
You chose Odysseus. Now let's get you running, not just reading.
Launch Kit tells you exactly where. The bridge between "I chose Odysseus" and "I'm using Odysseus". Not more documentation, but a decision-making kit. The first night should be about exploring, not troubleshooting.
Use Cookbook without guessing
Cookbook is one of the reasons users search for odysseus ai ollama models instead of only searching for Ollama. The official Odysseus README describes Cookbook as hardware-aware model recommendation and serving built around VRAM-aware fit scoring. That makes Cookbook useful when you do not want to guess which GGUF, FP8, or AWQ model might fit your machine.
Use Cookbook as a recommendation layer, not as a magic guarantee. Hardware detection depends on the runtime route. Docker must actually see your intended GPU. Apple Silicon users may prefer native Mac because Docker on macOS does not provide Metal GPU acceleration for local models. NVIDIA and AMD users need the host runtime and passthrough path to be correct before Cookbook results are meaningful.
A disciplined Cookbook workflow is: open Cookbook, review detected hardware, choose a recommended small model, download or serve it, test plain chat, then compare it with a known Ollama model. If Cookbook stalls on dependencies, downloads, or GPU libraries, do not assume Odysseus itself is broken. Fall back to a direct Ollama model or API provider while you diagnose the serve engine.
When API models beat local models
The strongest practical lesson from the video set is that local models are not always the right first brain. Odysseus can be local-first while still using API-backed models. If your machine is slow, has no usable GPU, or cannot fit the model you want, OpenRouter or another OpenAI-compatible provider can make the workspace usable immediately.
Use API fallback when you care more about answer quality than offline privacy, when agents need a stronger reasoning model, or when you are still learning the interface. Use Ollama when private local data, offline work, predictable cost, or model experimentation matters more. A mature Odysseus setup often has both: a small local model for private tasks and an API provider for harder agent or research work.
Do not paste API keys into public comments, screenshots, or shared logs. Keep secrets in the app settings or local environment only when you understand where they are stored. The model choice is not only a speed decision. It also controls what data leaves your machine.
Test models before agents
The first Odysseus AI Ollama models test should avoid every optional tool. Select the model, send a short prompt, and ask for a short answer. If the model replies quickly enough, then test a paragraph rewrite, a short coding question, and a small summarization task. Only after that should you enable agents, web, files, deep research, memory, or long-context tasks.
Save a known-good prompt. When you switch from Qwen to Gemma, from Ollama to OpenRouter, or from Docker to native Mac, run the same prompt again. This makes comparisons fair. If a later feature fails but the known-good prompt still works, the model route is probably fine and the issue is the tool or permission layer.
If a model produces slow but correct answers, lower your expectations before changing endpoints. If it produces connection errors, empty model lists, or immediate failures, focus on endpoint, pulled model names, Ollama server status, and Docker routing. Speed and connection are different failure classes.
What the videos add
The user-provided videos are useful because they map the search market. One video frames Cookbook as the answer to model guessing. One focuses on local models plus free API options and compares Odysseus with other tools. One focuses on the practical Ollama settings flow. Combined, they show that searchers do not only need a list of model names. They need a route from hardware to endpoint to first response.
This guide converts those ideas into a stable written workflow. It avoids copying scripts from videos, because video steps can age quickly and some model names are hype-driven. Use the videos for orientation and the official docs for current commands, model tags, and network behavior.
Cookbook-first angle: scan hardware, avoid guessing model fit, and use small models before trying heavier downloads.
Model strategy angle: local models, free API fallback, blind comparison, agents, research, memory, and model tradeoffs.
Ollama connection angle: open settings, add the local model endpoint, choose a model, test a simple prompt, then troubleshoot.
Troubleshooting model failures
If models do not appear, first confirm that Ollama has at least one pulled model. Run ollama list on the machine that hosts Ollama. If the list is empty, pull a model before blaming Odysseus. If the model exists, test it directly in Ollama before testing Odysseus.
If native Odysseus cannot connect to native Ollama, check whether Ollama is running and whether the base URL includes the OpenAI-compatible path. If Docker Odysseus cannot connect to host Ollama, replace localhost with host.docker.internal and make sure the host service accepts connections. If LAN access is involved, check firewall rules before changing application settings.
If the model responds but is unusably slow, change models before changing the whole install route. Try a smaller model, reduce context, close other heavy workloads, or move the difficult task to an API-backed provider. A slow 26B or 70B local model can make a working setup feel broken. A smaller model can often make the same Odysseus workflow useful.
FAQ
What are the best Odysseus AI Ollama models to start with?
Start with a small, current model from the official Ollama library, such as a compact Qwen, Gemma, Llama, or Phi-class model. The best first model is the one your machine can answer with quickly, not the largest model mentioned in a video.
Should I use Cookbook or Ollama models first?
Use Ollama first when you want a simple known endpoint and already know which model to pull. Use Cookbook when you want Odysseus to inspect hardware and recommend model fits, especially on machines with usable GPU or VRAM.
Why does Odysseus not see my Ollama models?
The most common causes are the wrong endpoint, missing /v1 path for OpenAI-compatible routing, no pulled models in Ollama, or Docker using localhost inside the container instead of the host machine.
Can Odysseus use OpenRouter instead of Ollama?
Yes. Odysseus can use local models or API-backed providers. OpenRouter is useful when your machine cannot run local models well, but API keys and provider account settings should be treated as secrets.
Is a 26B or 70B model a good first local model?
Usually no. Large models can be useful on strong hardware, but beginners should prove the route with a smaller model first. Slow inference is often a hardware bottleneck, not an Odysseus bug.
Use this odysseus ai ollama models guide when the app already runs and your next decision is which model brain to use. Use the Ollama endpoint guide when the connection itself is failing. Use the setup guide when Docker, native Windows, Mac, Python, or first login are still unresolved.